Gartner Data Integration Magic Quadrant 2025 - A Qlik újabb vezetői helyezése
Az adatintegrációs eszközök továbbra is alapvető elemei a céges architektúráknak, mivel egyre fontosabbak a továbbfejlesztett képességek a működési, elemzési és mesterséges intelligencia alkalmazási esetek támogatásához.
Stratégiai feltételezés
2027-re az adatintegrációs eszközökbe épített AI asszisztenseknek és munkafolyamatoknak köszönhetően 60%-kal csökken a manuális beavatkozások szükségessége, és ezáltal elérhetővé válik az önkiszolgáló adatkezelés.
A piac meghatározása/leírása
Az adatintegrációs eszközök piaca olyan önálló szoftvertermékekkel foglalkozik, amelyek lehetővé teszik a szervezetek számára, hogy több forrásból származó adataikat kombinálják, valamint segítik az adathozzáféréssel, adatátalakítással, adatdúsítással és adatszolgáltatással kapcsolatos feladataik teljesítését. Az adatintegrációs eszközök használata lehetővé teszi az adatok előkészítését, az operatív adatintegrációt, a modern adatarchitektúrák megvalósítását, valamint a kevésbé technikai jellegű adatintegrációt is. Az adatintegrációs eszközöket az adat- és elemzési vezetők és csapataik szerzik be data engineer-ek és kevésbé technikai felhasználók, például üzleti elemzők vagy data scientist-ek számára. Ezek a termékek SaaS-ként, helyben, nyilvános vagy privát felhőben, illetve hibrid konfigurációkban is telepíthetők.
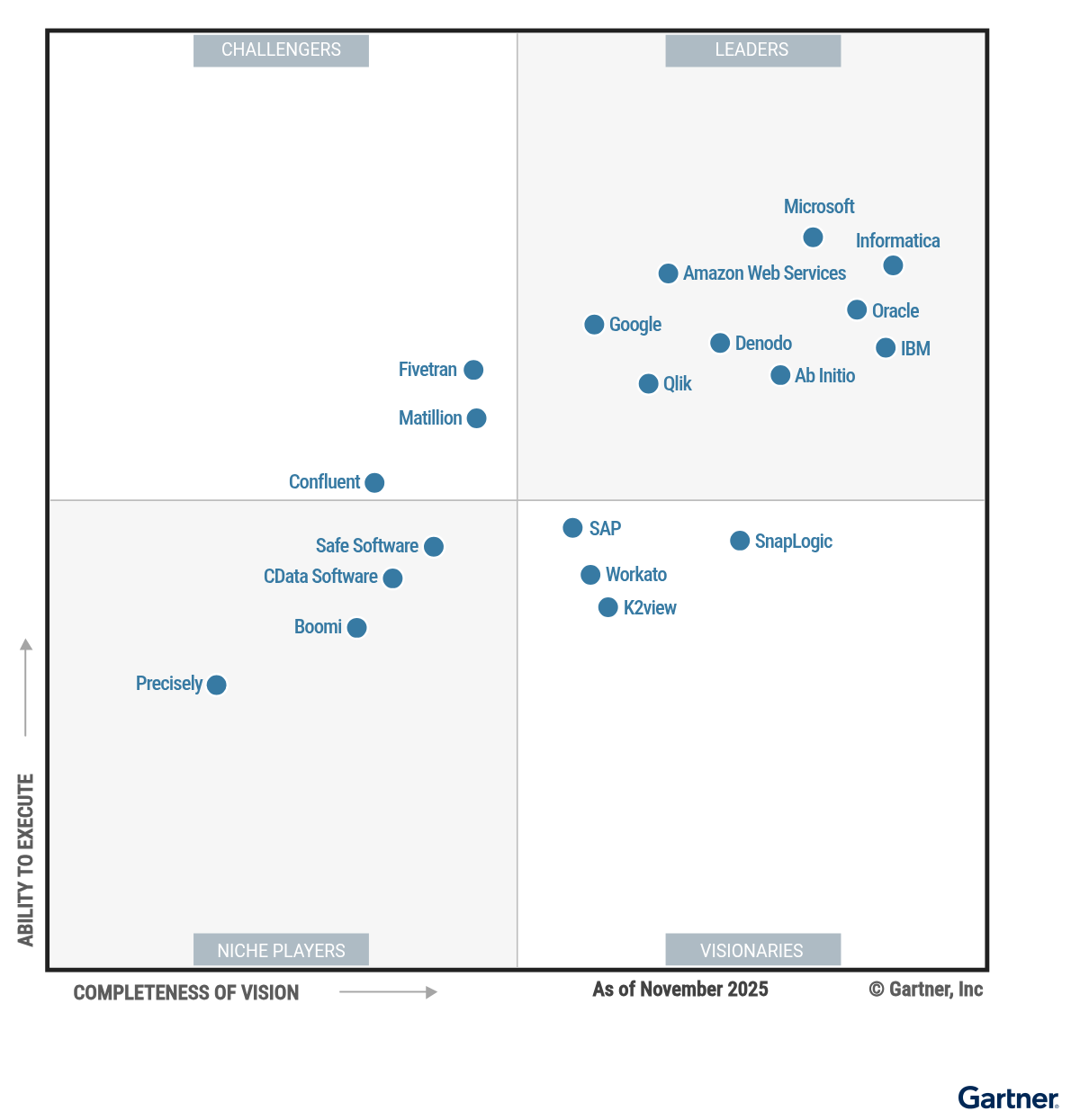
Qlik
A Qlik vezető szerepet tölt be ebben a Magic Quadrant-ben. Adatintegrációs termékei között megtalálható a Qlik Talend Cloud, a Talend Data Fabric és a Qlik Replicate. A termékfejlesztés nagy része a Qlik legújabb termékére, a Qlik Talend Cloudra koncentrálódik.
A Qlik tevékenységi területe földrajzilag sokszínű, jelentős jelenléttel rendelkezik Európában és Észak-Amerikában, és minden iparágban támogatja ügyfeleit. A Qlik jelenlegi prioritásai között szerepel az ügyfelek támogatása a végpontok közötti adatkezelési kezdeményezésekben, például a lakehouse modernizációjának támogatása és megbízható adattermékek fejlesztése. Emellett továbbra is befektet új AI-funkciókba, például az adatcsatornák építéséhez szükséges Agentic AI-ba.
Erősségek
- erős adatmásolási/szinkronizálási képességek: a Qlik adatmásolási és szinkronizálási képességei, beleértve a fejlett naplóalapú CDC-t, a piac legerősebbjei közé tartoznak. A platform nagy teljesítményű, nagy sebességű naplóalapú CDC-t biztosít a szinte valós idejű adatmozgáshoz, biztosítva az időszerű és megbízható adatátvitelt. Ezek a képességek olyan projekteket támogatnak, mint az adatbázis-migrációk, a valós idejű elemzések és a hibrid felhőalapú forgatókönyvek;
- holisztikus látásmód: a Qliket az adatkezelés terén egy stabil és meggyőző vízió vezérli, amely nagy hangsúlyt fektet olyan támogató funkciókra, amelyek más gyártóknál gyakran háttérbe szorulnak, pl. a metaadatok kezelése és az adatgazdálkodás. Nemrégiben, az Upsolver felvásárlását követően a Qlik Talend Cloud részeként bevezetett Qlik Open Lakehouse szintén bizonyítja a Qlik elkötelezettségét amellett, hogy ügyfelei előremutató, modern lakehouse architektúrákat építhessenek az Apache Iceberg-re;
- átfogó termékfunkciók: A Qlik robusztus tömeges/kötegelt adatmozgatást, fejlett átalakítási funkciókat és sokféle csatlakozót kínál különböző forrásokhoz és célokhoz. A piac régóta vezető szereplőjeként a Qlik úgy mutat érettséget az adatintegráció terén, hogy kevés jelentős gyengesége van.
Az adatintegrációs eszközök által kezelt gyakori problémák a következők:
- data engineer-ek munkája — technikai felhasználók általi adatintegráció az adatcsatornák fejlesztése, kezelése és optimalizálása céljából, főként elemzési felhasználási esetekhez
- modern adatkezelési architektúrák létrehozása — adatintegráció a modern adatkezelési megoldások, úgymint lakehouse, adatszövet és adatháló létrehozása érdekében;
- önkiszolgáló adatintegráció — adatintegrációs tevékenységek kevésbé technikai felhasználók által különböző analitikai igények kielégítése érdekében: analitikai és üzleti intelligencia (ABI), valamint adattudományi felhasználási esetek;
- operatív adatintegráció — modern adatkezelési architektúrák létrehozása - adatintegráció a modern adatkezelési megoldások, úgymint lakehouse, adatszövet és adatháló létrehozása érdekében;
- AI-projektek támogatása — Adatintegráció komplex követelményekkel rendelkező AI-projektek támogatásához, például csevegőrobotok vagy ajánlórendszerek építéséhez, valamint AI-kompatibilis adatok szállításához.
Az adatintegrációs eszközök kötelező jellemzői:
- adatkinyerés, adatbevitel és adatátadás támogatása több általános adatintegrációs stílus használatával: pl. tömeges/kötegelt adatmozgatás, adatreplikáció és szinkronizálás, folyamadatok integrációja és adatvirtualizáció. Ez a funkció magában foglalja a kész és konfigurálható csatlakozók elérhetőségét az adatforrások és célpontok zökkenőmentes eléréséhez;
- adattranszformáció támogatása: pl. karakterlánc-manipuláció, számítás, adatforrás-összevonás, adataggregáció, komplex elemző, szövegbányászat és többséma-adatmodellezés. Ez a funkció előre elkészített, újra felhasználható, konfigurálható és egyedi komponensek segítségével is használható;
Az adatintegrációs eszközök általános funkciói a következők:
- bővítési funkcióik generatív mesterséges intelligenciát (GenAI) és előre elkészített ML-algoritmusokat használnak, amelyek automatikusan generálják az adatfolyamatok kódját és dokumentációját, optimalizálják az adatintegrációs műveleteket (pl. anomália-felismerés, automatikus felderítés), továbbá természetes nyelvet alkalmaznak az adatok lekérdezéséhez és átalakításához. Ezek a funkciók egyszerűsítik a feladatokat és elrejtik a komplexitást, a használhatóság növelése érdekében;
- metaadat-kezelési funkcióik a technikai és működési metaadatok (pl. használati adatok, tranzakciós naplók, rendszerterhelések) valamint az üzleti metaadatok (pl. szójegyzék) széles körű felkutatását, elérését, használatát és megosztását támogatják, akár beágyazott adatkatalógusokkal, akár a metaadatok jól integrált külső rendszerek számára történő feltárásával.
- adatkezelési funkcióik támogatják az adatkezelési megbízásokat (pl. adatminőség, adatvonal, házirendek érvényesítése, maszkolás és megjegyzések), miközben az adatokat speciális felhasználási esetek (pl. törzsadatok kezelése) teljesítéséhez is figyelik;
- dataOps funkcióik támogatja a data pipeline működését, úgymint az adatokkal kapcsolatos objektumok változáskezelését (pl. data pipeline Git-integrációja, adatmodell-kezelés), az automatizálást (pl. automatizált tesztelés) és az adatszolgáltatások megfelelő szintű biztonsággal történő összehangolását (pl. folyamatos integrációs/folyamatos szállítási [CI/CD] pipeline);
- FinOps funkcióik lehetővé teszik az adat- és elemzési vezetők számára, hogy iteratív módon nyomon kövessék, ellenőrizzék és optimalizálják kiadásaikat, megértsék a termék teljesítményét, és megfelelő döntéseket hozzanak az ár és a teljesítmény, valamint az adatintegrációs; munkaterhelések tekintetében, az erőforrások optimális elosztását eredményezve.
- AI-központú funkciók strukturálatlan adatokat dolgoznak fel és vektoros adatbázisokba töltik be, valamint AI-modelleket fejlesztenek (például nagy nyelvi modellek - LLM). Ezek a funkciók magukban foglalják a adatlekérésre alapozott generálást (RAG) architektúrák megvalósításának támogatását és a Model Context Protocol-hoz (MCP) hasonló interfészeken keresztüli interakciókat.